



How Discord ML Hit Its Scaling Limit
At Discord, our machine learning systems have evolved from simple classifiers to sophisticated models serving hundreds of millions of users. As our models grew more complex and datasets larger, we increasingly ran into scaling challenges: training jobs that needed multiple GPUs, datasets that wouldn’t fit on single machines, and computational demands that outpaced our infrastructure.
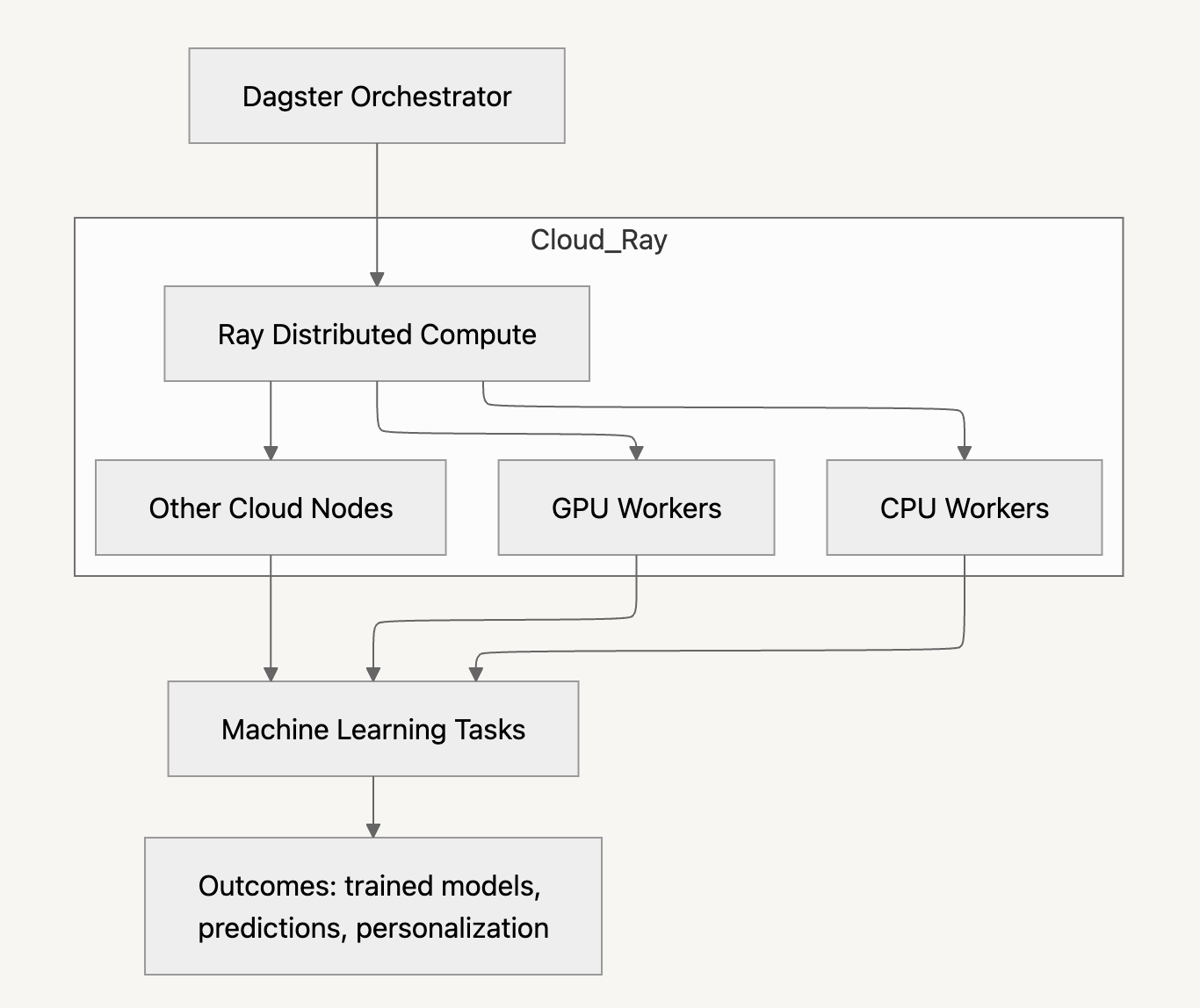
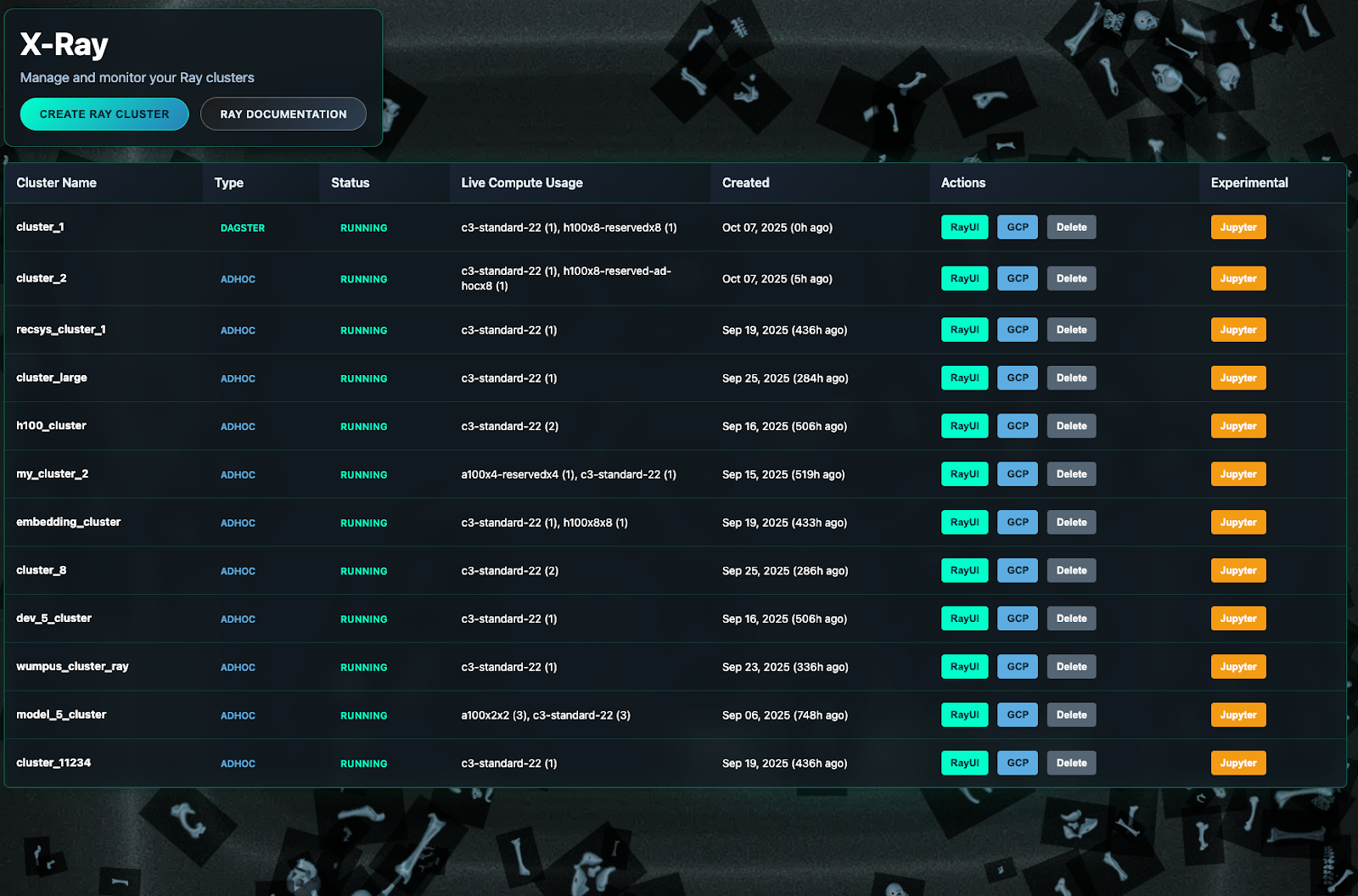
Access to distributed compute was necessary — but not sufficient. We needed distributed ML to be easy. Ray, an open-source distributed computing framework, became our foundation. At Discord, we built a platform around it: custom CLI tooling, orchestration with Dagster + KubeRay, and an observability layer called X-Ray. Our focus was on developer experience, turning distributed ML from something hard to use into a system they are excited to work with.
This is how Discord went from no deep learning, to ad-hoc experiments, to a production orchestration platform, and how that work enabled models like Ads Ranking that delivered a +200% improvement on our business metrics.









.png)
.png)











Nameplates_BlogBanner_AB_FINAL_V1.png)

_Blog_Banner_Static_Final_1800x720.png)


_MKT_01_Blog%20Banner_Full.jpg)




























.png)














